用N-API开发低延迟音频播放库
- Published on
- Authors
- Name
- 0neSe7en
- @0ne_Se7en


前言
最近公司正在使用electron做一个直播用的客户端。在mainProcess从服务器拉取用户的音频数据(PCM)然后播放。所以考虑实现一个Node的音频播放器:node-sdl-speaker
其实现在已经有一个业界使用广泛且高质量的音频库node-speaker,但是它有几点不满足我的需求:
- 跨平台。因为是electron项目,所以需要在客户端中直接集成相应的音频播放库。而
node-speaker虽然可以跨平台,但是比较麻烦,不太适合electron。 - 直播(强实时)。这个库的设计目的更倾向于播放一个文件,是使用者主动写数据,但有的场景需要把当前未播放的数据直接清空,此库不支持。
- 多声道。因为是直播嘛,可能会有多个人在同时说话。而
node-speaker目前不支持多声道混音。
这篇文章主要分为两部分,一部分是Node.js与node-addon-api,另一部分是使用 SDL2 实现一个低延迟的多音源播放器。大家各取所需~
所需知识
- 比较了解Node.js
- 一些简单的C++知识
面向README编程
这个库采用面向README编程(RDD) 。所以先整理一下需要的功能以及接口。
功能
- 使用SDL做音频的backend。跨平台
- 支持Stream。可以 pipe 一个 PCM Stream到一个音频通道
- 支持多声道,对多个声道进行混音
- 低延迟
对应的接口:
Speaker.init():初始化音频播放器Speaker.start(),Speaker.stop,Speaker.pause(),Speaker.resume():播放器的开始停止控制Speaker.register(name) -> audioChannel:注册一个声道Speaker.detach(name):移除一个声道audioChannel.write(buffer)Speaker.cleanAll():清空数据
如何使用Node.js编写原生模块
之前此库采用NAN进行开发,在Github中可以看到以前采用NAN的代码。我自己并不擅长C++,在使用NAN的时候,总是需要直接使用V8和libuv(这个几乎不会用到,但是很多开发者会直接使用libuv的方法)。对于我来讲,没有统一的API在编写时是比较痛苦的。
不过 Node 8.x 加入了N-API用来取代NAN,并且现在的Node 10.x,N-API已经进入Stable阶段。所以是时候尝试一下了。不过N-API是一个C API,而我更喜欢C++的API,所以采用官方推荐的 node-addon-api
The N-API is a C API that ensures ABI stability across Node.js versions and different compiler levels. However, we also understand that a C++ API can be easier to use in many cases. To support these cases we expect there to be one or more C++ wrapper modules that provide an inlineable C++ API. Binaries built with these wrapper modules will depend on the symbols for the N-API C based functions exported by Node.js. These wrappers are not part of N-API, nor will they be maintained as part of Node.js. One such example is: node-addon-api.
node-addon-api
一些相关的链接:
- abi-stable-node-addon-examples 这里有一些基本的node-addon-api的例子,也可以看到node-addon-api、N-API、NAN的对比。如果后面有看不懂的地方,随时查看这个example repo。
- GYP 这个是GYP的官网。在编写
binding.gyp的时候,可能会需要查阅。
写一个Demo
在开始写正式代码之前,先写一个小Demo,把各种可能的小困难都解决。比如...实现一个 Writeable Stream:能够 pipe 一个流,并把这个流的数据发送给native,然后native输出每一次写入的长度。可以直接看 simple-writeable-stream
JavaScript的代码非常简单:
const { Writable } = require('stream');
const stream = require('bindings')('stream'); // 使用 bindings 可以很方便的找到编译出来的 .node 文件,不管是使用release还是debug模式编译
module.exports = class SimpleStream extends Writable {
_write(buf, encoding, next) { // 直接覆盖一下_write方法。https://nodejs.org/api/stream.html#stream_implementing_a_writable_stream
stream.write(buf);
next();
}
};
{
"targets": [
{
"target_name": "stream", // 编译出来的.node文件的名称。需要和上面bindings使用的名称一样。
"cflags!": [ "-fno-exceptions" ],
"cflags_cc!": [ "-fno-exceptions" ],
"xcode_settings": { "GCC_ENABLE_CPP_EXCEPTIONS": "YES",
"CLANG_CXX_LIBRARY": "libc++",
"MACOSX_DEPLOYMENT_TARGET": "10.7"
},
"msvs_settings": {
"VCCLCompilerTool": { "ExceptionHandling": 1 }
},
"sources": [
"stream.cc" // 需要被编译的文件
],
"cflags": [ "-Wall", "-std=c++11" ],
"include_dirs": [
"<!@(node -p \"require('node-addon-api').include\")" // 需要包含的头文件目录。
]
}
]
}
相应的,C++的代码是这样的:
#include <napi.h>
#include <iostream>
#define EXPORT_METHOD(NAME, FUNC) \
exports.Set(Napi::String::New(env, #NAME), Napi::Function::New(env, FUNC));
#define STATUS Napi::Number::New(info.Env(), r);
Napi::Value Write(const Napi::CallbackInfo& info) {
// 关于Buffer的文档可以在这里看到:https://github.com/nodejs/node-addon-api/blob/master/doc/buffer.md#data
void* buffer = info[0].As<Napi::Buffer<uint8_t >>().Data(); // 从 Data() 中可以取到Buffer的数据
size_t length = info[0].As<Napi::Buffer<uint8_t >>().Length(); // 从 Length() 中可以取到Buffer的长度
std::cout << "length:" << length << std::endl; // 输出收到的Buffer长度
return Napi::Number::New(info.Env(), length);
}
Napi::Object InitAll(Napi::Env env, Napi::Object exports) {
EXPORT_METHOD(write, Write); // 让 `write` 函数指向Write
return exports;
}
NODE_API_MODULE(stream, InitAll) // 注册一个名叫stream的module
然后执行 node-gyp rebuild。 随便写个JavaScript测试一下就搞定咯。比如:
const fs = require('fs');
const SimpleStream = require('./index');
const stream = new SimpleStream();
fs.createReadStream('./test').pipe(stream);
开始编写模块接口
我们先把需要C++提供的接口列出来,并把基本的C++函数声明好。
init(sampleRate, channels, samplesPerFrame, format)addChannel(name)removeChannel(name)start()stop()pause()resume()write(channelName, buffer)clean(channelName)cleanAll()
#include <napi.h>
#define EXPORT_METHOD(NAME, FUNC) \
exports.Set(Napi::String::New(env, #NAME), Napi::Function::New(env, FUNC));
#define STATUS Napi::Number::New(info.Env(), r);
// 可以把CallbackInfo简单的理解为就是参数列表。是一个数组。
Napi::Value InitSpeaker(const Napi::CallbackInfo& info) {
// Napi::Env 是对 napi_env的一个封装,官方文档:https://nodejs.org/api/n-api.html#n_api_napi_env
// 我个人对它的理解,是一个N-API的调用,会对应一个env,各种和vm状态相关的操作(比如创建新的对象等)都需要使用这个env。
// 就像文档中的描述一样,是一个用来保存vm状态的context
Napi::Env env = info.Env();
int freq = info[0].As<Napi::Number>().Int32Value(); // 一次把四个参数解析为期望的类型。
uint32_t channels = info[1].As<Napi::Number>().Uint32Value();
uint32_t samples = info[2].As<Napi::Number>().Uint32Value();
uint32_t format = info[3].As<Napi::Number>().Uint32Value();
return Napi::Number::New(env, 0);
}
Napi::Value Write(const Napi::CallbackInfo& info) {
void* buffer = info[1].As<Napi::Buffer<uint8_t >>().Data(); // 取出Buffer
size_t length = info[1].As<Napi::Buffer<uint8_t >>().Length(); // 以及Buffer长度,用于后续写入SDL播放器
std::string ch_name = info[0].As<Napi::String>().ToString(); // channel的名称
return Napi::Number::New(info.Env(), 0);
}
void Clean(const Napi::CallbackInfo& info) {
std::string ch_name = info[0].As<Napi::String>().ToString(); // 获取channel的名称,用于后续清理
}
Napi::Value AddChannel(const Napi::CallbackInfo& info) {
std::string ch_name = info[0].As<Napi::String>().ToString(); // 注册一个Channel,用于写入数据。
int r = speaker.NewChannel(ch_name);
return STATUS;
}
Napi::Value RemoveChannel(const Napi::CallbackInfo& info) {
std::string ch_name = info[0].As<Napi::String>().ToString();
int r = 0;
return STATUS;
}
Napi::Value Start(const Napi::CallbackInfo& info) {
int r = 0;
return STATUS;
}
// Stop, Pause, Resume都是一样的
// ...
Napi::Object InitAll(Napi::Env env, Napi::Object exports) { // 把上面声明的各种方法,都绑到 exports 上
EXPORT_METHOD(init, InitSpeaker);
EXPORT_METHOD(addChannel, AddChannel);
EXPORT_METHOD(removeChannel, RemoveChannel);
EXPORT_METHOD(start, Start);
EXPORT_METHOD(stop, Stop);
EXPORT_METHOD(pause, Pause);
EXPORT_METHOD(resume, Resume);
EXPORT_METHOD(write, Write);
EXPORT_METHOD(clean, Clean);
EXPORT_METHOD(cleanAll, CleanAll);
return exports;
}
NODE_API_MODULE(sdl_speaker, InitAll)
C++的接口大致就是这些,现在把JavaScript部分的业务逻辑做一个简单的封装,让用户使用起来更顺手。如果采用 RDD 的模式进行开发写好了README.md,这一步在这个项目里就相当无脑了。
我只把重要的地方贴一下,具体的可以直接 clone 此项目来看。代码量非常少。
// wrapper.js
const wrapper = require('bindings')('sdl-speaker.node');
module.exports = wrapper;
// Channel.js
const sdl = require('./wrapper');
const { Writable } = require('stream');
module.exports = class Channel extends Writable {
// 自定义的WriteableStream,用于支持pipe
// 需要传入channel的名称,用于后续写入到Buffer中
constructor(name, streamOption) {
super(streamOption);
this.name = name;
}
clean() {
sdl.clean(this.name);
}
_write(buf, encoding, next) {
sdl.write(this.name, buf);
next();
}
}
// index.js
const sdl = require('./wrapper');
const Channel = require('./Channel');
const Speaker = module.exports = {};
const channels = new Map(); // 会在JavaScript这里,单独保存channel的列表。避免向C++层多余的调用。
/**
* Init Speaker
* @param {Object} opts
* @param {Number} [opts.sampleRate = 16000]
* @param {Number} [opts.channels = 1]
* @param {Number} [opts.samplesPerFrame = 1024]
* @param {Number} [opts.format = AUDIO_S16] - you can find more audio format from `Speaker.AudioFormats`
*/
Speaker.init = (opts, onError) => {
opts = opts || {};
const sampleRate = opts.sampleRate || 44100;
const channels = opts.channels || 2;
const samplesPerFrame = opts.samplesPerFrame || 1024;
const format = opts.format || Speaker.AudioFormats.AUDIO_S16;
return sdl.init(sampleRate, channels, samplesPerFrame, format);
}
/**
* Register a channel for the speaker. All channels is identified by name.
* @param {String} name
* @return {Channel}
*/
Speaker.register = (name) => {
if (channels.get(name)) {
throw new Error(`Channel [${name}] is exists`);
}
channels.set(name, new Channel(name));
sdl.addChannel(name); // 实际向C++注册Channel
return channels.get(name);
}
/**
* Detach a channel from the speaker.
* @param {String|Channel} channel
*/
Speaker.detach = (channel) => {
if (channel instanceof Channel) {
sdl.removeChannel(channel.name);
} else {
sdl.removeChannel(channel);
}
}
/**
* Start Speaker.
*/
Speaker.start = () => {
const res = sdl.start();
if (res === -1) {
throw new Error('Current State is not Stop');
} else if (res === -2) {
throw new Error('SDL OpenAudio Failed');
}
}
Speaker.AudioFormats = {
AUDIO_S16: 0x8010,
AUDIO_S32LSB: 0x8020,
AUDIO_S32MSB: 0x9020,
AUDIO_S32: 0x8020
// ...
}
到这为止,除了播放器本身的功能外,已经全部完成。如果对SDL感兴趣的同学,可以继续往下看。
SDL部分
如前言所说,这个库是为了直播时播放音频。所以与播放一个完整的歌曲最大的不同是,播放歌曲需要声音是连续的,而直播中,如果卡顿,那么前面那些声音应该丢弃掉。
举个例子:我正在直播看世界杯,因为各种原因网络卡顿没有声音。5s后,网络恢复,一下子收到刚才卡顿5s的数据,这时我应该继续播放这5s的数据,还是马上开始播放最新的0.5s,而中间的4.5s就直接丢弃。我个人的选择是后者,丢弃中间卡顿的4.5s数据,直接开始播放最新音频。如果不这么做,用户听到的直播声音就会比其他人延迟5s,就会比其他人更晚的知道球进了。
所以会使用如下两个方式:
- 使用环形Buffer。性能好、预先分配固定大小内存。因为上述的场景,如果我收到的Buffer大于环形Buffer的capacity,就可以直接覆盖旧数据。
- 使用SDL的AudioCallback( https://wiki.libsdl.org/SDL_AudioSpec )。这样SDl需要播放多少数据,就从Buffer中取出多少数据,而不用一次性把Buffer中所有数据都写入。可以随时清空Buffer。
音频播放
这里可以看一下SDL播放音频的核心代码
#include <SDL2/SDL.h>
#include "hlring/rbuf.h" // 环形buf的库
// 这是SDL用于取音频数据的回调函数. SDL在需要新的音频数据时,会调用此函数。此函数会填充音频数据。
// udata 是一个指针。你可以往里面存任何你自己的数据。之后这里会存所有channel的列表
// stream 这是SDL期望被填充的数据。把音频数据都填到这里就行
// len stream的长度
// 顺便说下,这个地方SDL的处理方式和Unity是一样的 https://docs.unity3d.com/ScriptReference/AudioClip.PCMReaderCallback.html
static void fill_audio(void *udata, Uint8 *stream, int len) {
auto *src = new unsigned char[len]; // 首先创建len长度的空间,用于从rbuf中取数据
SDL_memset(stream, 0, static_cast<size_t>(len)); // 先把 stream 设置为0,也就是静音。
rbuf_read(it->second->buffer, src, len); // 从rbuf中读取len长度的数据。如果len小于rbuf剩余的buffer数,那么就不会被填充。用户听起来就是没声音。
SDL_MixAudioFormat(
stream,
static_cast<const Uint8 *>(src),
AUDIO_S16LSB,
static_cast<Uint32 >(len),
SDL_MIX_MAXVOLUME
); // 这是使用SDL的音频混音功能。将音频数据写入到stream中。目前我把多通道的代码去掉了。使用多通道的时候,就通过这个混音功能,把多个音源的声音合并成一个。
delete[] src;
}
static SDL_AudioCallback audio_callback_ptr = fill_audio;
class SDLSpeaker {
public:
int Start() {
if (int errorCode = SDL_OpenAudio(&wanted_spec, NULL) < 0) { // 初始化SDL音频设备。如果 wanted_spec 不满足系统的需求,则会报错。
SDL_Log("Audio Device Open failed %d: %s", errorCode, SDL_GetError());
return -2;
}
SDL_PauseAudio(0); // 开始播放。不调用此函数的话,SDL就处在Pause状态
return 0;
};
const char* Init(int freq, uint32_t channels, uint32_t samples, uint32_t format) {
if (SDL_Init(SDL_INIT_AUDIO | SDL_INIT_TIMER)) { // 初始化SDL,我只需要它的Audio和Timer两个功能
const char* err = SDL_GetError();
return err;
}
wanted_spec.freq = freq;
wanted_spec.format = static_cast<SDL_AudioFormat >(format);
wanted_spec.channels = static_cast<Uint8 >(channels);
wanted_spec.silence = 0;
wanted_spec.samples = static_cast<Uint16>(samples);
wanted_spec.userdata = &channels_map; // 通道的map
wanted_spec.callback = audio_callback_ptr; // 回调函数的函数指针
return nullptr;
};
private:
SDL_AudioSpec wanted_spec;
};
多音源
接下来加入多音源的支持。刚刚在上面的代码中,已经用到了 SDL_MixAudioFormat 方法。此方法就是专门用来混音的。
可以看一下下面的流程图,就是支持多音源后的样子:
- 每一个音源都对应一个Channel
- 音源的数据写入到Channel的环形Buffer中
- SDL定期调用
fill_audio fill_audio从所有Channel中,依次从环形Buffer中读取len长度的Buffer数据- 对取到的Buffer数据写入SDL提供的Buffer中,并混音
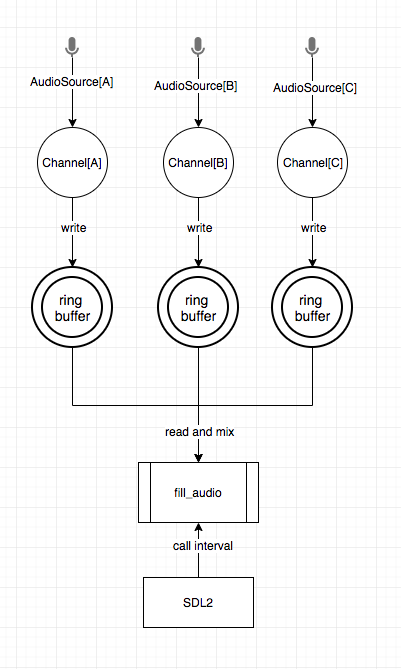
那么对应的C++代码就需要变为如下内容:
// Channel.h
class Channel {
public:
explicit Channel(std::string ch_name) {
name = ch_name;
// 创建对应的环形Buffer。320是我们项目中一个音频帧的长度
buffer = rbuf_create(320 * 10000);
};
~Channel() {
clean();
rbuf_destroy(buffer);
};
int write(void * buf, int32_t length) {
// 把数据写入到rbuf中,并返回rbuf的剩余空间
rbuf_write(buffer, static_cast<unsigned char*>(buf), length);
return rbuf_available(buffer);
};
int clean() {
rbuf_clear(buffer);
return 0;
};
std::string name;
rbuf_t *buffer;
};
// SDLSpeaker
bool need_mix(rbuf_t *buf, int len) {
// 如果此Channel剩余的Buffer大于需要获取的Buffer,则对齐进行混音
// 但是要注意,这里会有一个潜在问题
// 可能会导致某个Channel的声音播放比其他Channel要滞后
return rbuf_used(buf) >= len;
}
static void fill_audio(void *udata, Uint8 *stream, int len) {
// 从 `udata` 中取出channel列表。`fill_audio` 这个函数,是在其他线程执行的。
auto *channels_map_ptr = static_cast<std::unordered_map<std::string, Channel*> *>(udata);
auto *src = new unsigned char[len];
SDL_memset(stream, 0, static_cast<size_t>(len));
// 遍历channels列表,依次执行SDL_MixAudioFormat
for (auto it = channels_map_ptr->begin(); it != channels_map_ptr->end(); ++it) {
if (need_mix(it->second->buffer, len)) {
rbuf_read(it->second->buffer, src, len);
SDL_MixAudioFormat(
stream,
static_cast<const Uint8 *>(src),
AUDIO_S16LSB,
static_cast<Uint32 >(len),
SDL_MIX_MAXVOLUME
);
}
}
delete[] src;
}
// 为了方便,我把.h 和 .cpp 写在一起
class SDLSpeaker {
public:
// ...
enum CurrentPlayState { stop, pause, playing };
// 找到Channel,写数据
int Write(void * buf, int32_t length, string channel_name) {
Channel* ch = find_channel(channel_name);
if (ch != nullptr) {
return ch->write(buf, length);
}
return -1;
};
void Clean(string channel_name) {
// 找到Channel,清数据. 代码略
};
int NewChannel(string channel_name) {
auto got = channels_map.find(channel_name);
if (got == channels_map.end()) {
Channel* channel = new Channel(channel_name);
channels_map[channel_name] = channel;
return 0;
} else {
return -1;
}
};
int RemoveChannel(string channel_name) {
auto got = channels_map.find(channel_name);
if (got == channels_map.end()) {
return -1;
} else {
delete got->second;
channels_map.erase(channel_name);
return 0;
}
};
CurrentPlayState state = stop;
private:
Channel* find_channel(string) {
auto got = channels_map.find(name);
if (got == channels_map.end()) {
return nullptr;
} else {
return got->second;
}
};
SpeakerOpt option;
SDL_AudioSpec wanted_spec;
std::unordered_map<std::string, Channel*> channels_map;
};
总结
那么,整个这个库就算是写完了。剩下需要补充一些开源库必备的东西了:
- Travis-CI:非常好用的CI工具
- GreenKeeper:检查项目中是否有需要升级的依赖
README.md:详细的API与使用说明npm publish- 测试...
// TODO